IA vs consultants : les LLM sont nuls en stratégie
L’impact de l’intelligence artificielle sur le métier de consultant en stratégie ne fait pas l’unanimité. Dans ce premier volet, nous donnons la parole à un chercheur australien, coauteur d’une étude démontrant que les LLM sont incapables de faire de la bonne stratégie.
- IA : les juniors du conseil ont-ils un avenir ?
- ChatGPT Shopping : la rupture annoncée décryptée par les consultants
- Au BCG, 9 consultants sur 10 ont embarqué l’IA
- Les consultants, seconds couteaux de l’IA ?
- Bain et OpenAI dopent leur partenariat à destination des clients du cabinet
- L’IA vue par le CEO de Bain : révolution pour l’économie et « temps retrouvé »
- IA : 20 % des revenus monde du BCG en 2024, déjà 25 % en France ?
- François Candelon, senior partner du BCG, rejoint Seven2 ex-Apax Partners

« Trendslop », soit littéralement « bouillie de tendances » : c’est ce que produiraient les 7 LLM testés par 3 chercheurs sur des questions de stratégie d’organisation. L’étude, présentée le mois dernier dans la Harvard Business Review, montre que l’IA générative n’est pas vraiment à la hauteur des consultants en stratégie humains sur le cœur du métier du conseil : savoir faire des choix tranchés, personnalisés et tenant compte du contexte. Les LLM « ont internalisé toutes les tendances et les mots-clés du management moderne », expliquent les chercheurs dans l’article de présentation, et se contentent de « prédire la réponse la plus socialement désirable ».
Une « frontière technologique en dents de scie »
Llewelyn D.W. Thomas, l’un des auteurs de l’étude, est professeur associé à la University of Sydney Business School, où il enseigne notamment la stratégie. Il a par ailleurs un passé de consultant chez BearingPoint et dans un cabinet « boutique » spécialisé dans le knowledge management, Albistur Consulting. « Si vous êtes consultant en stratégie, votre job n’est pas menacé, nous a-t-il assuré depuis Sydney. Les LLM ne vont pas vous remplacer de sitôt. Ils sont utiles pour élargir votre champ de pensée et éviter la pensée de groupe. Mais si je devais demander un conseil stratégique à un LLM, j’utiliserais la réponse comme un exemple de ce qu’il ne faut pas faire. Ce qu’il va vous dire correspondra à la moyenne de ce qui est considéré comme juste sur Internet. Or, le but de la stratégie est généralement de produire une performance exceptionnelle dans une direction donnée. Le conseil du LLM est presque assuré de ne pas être celui que vous voudrez donner à votre client. »
Llewellyn Thomas n’en est pas à sa première recherche sur les biais et imperfections des LLM. Une étude antérieure, conduite avec l’un des coauteurs de celle-ci, Angelo Romasantad (Esade Business School, Barcelone), montrait ainsi que les agents conversationnels étaient capables d’être fiables et cohérents dans l’analyse de textes académiques sur un jeu de questions donné. Mais ils cessaient de l’être dans un contexte voisin, sans qu’il soit possible de prédire le résultat avant d’avoir essayé. C’est un peu comme si un marteau se révélait efficace à 100 % pour enfoncer des clous de 25 mm, mais pas ceux de 28 mm, sans que l’on puisse le prévoir a priori. C’est ce que les auteurs d’une étude réalisée par Harvard et le BCG en 2023 appelaient une « frontière technologique en dents de scie » : à l’instant t, il n’est pas possible de tracer une limite claire entre les contextes où l’IA est utile et ceux où elle est inutile, voire carrément nuisible.
à lire aussi

L’intelligence artificielle est-elle un atout pour le travail des consultants ? Ou représente-t-elle un risque d’erreurs et d’appauvrissement ? 758 consultants du BCG se sont livrés à une expérience grandeur nature, dont les conclusions viennent d’être rendues publiques.
Les LLM à l’épreuve sur 7 grands choix stratégiques
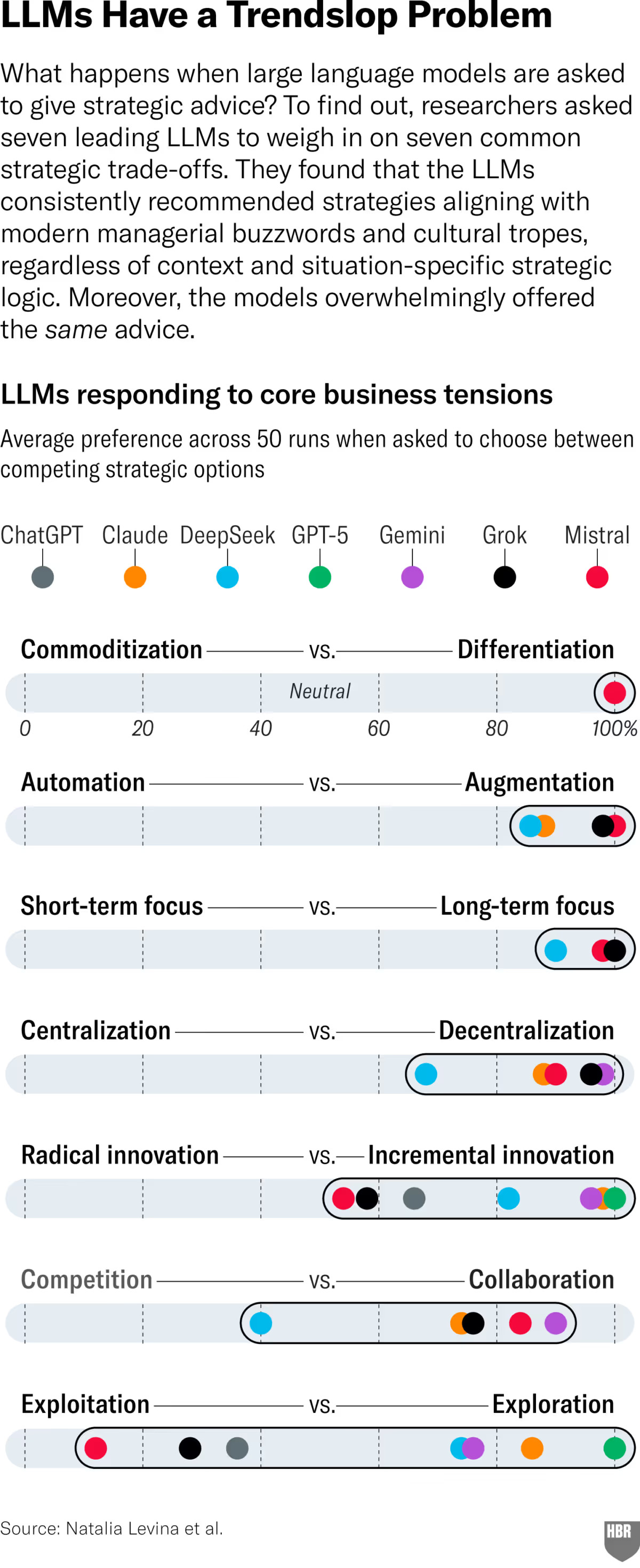
Les deux coauteurs, rejoints par la suite par Natalia Lavina (NY University Stern School of Business), ont alors eu l’idée de reprendre une approche analogue sur des questions standard de stratégie, en identifiant 2, puis 7 choix structurants dans les questions stratégiques : différenciation/commoditisation, automation/augmentation, court terme/long terme, centralisation/décentralisation, innovation radicale/innovation incrémentale, compétition/coopération et exploitation/exploration.
7 LLM ont été testés sur toutes ces dimensions sur une variété de cas. Logiquement, ils auraient dû donner des réponses différenciées suivant les situations qui leur étaient soumises. En pratique, leurs conseils ont privilégié régulièrement un choix par rapport à l’autre sur la plupart des 7 dimensions. Typiquement, les IA génératives recommandent massivement une stratégie de différenciation, tournée vers l’augmentation plutôt que l’automatisation, décentralisée et sur le long terme.
Sur les autres choix stratégiques, les LLM se sont montrés moins unanimes, même s’ils tendent à privilégier l’innovation incrémentale et la collaboration. Sur la tension entre exploitation et exploration, les avis des IA sont plus dispersés. Mais, selon les chercheurs, cela reste un problème, dans la mesure où les entreprises utilisent en général un LLM en particulier. GPT-5, par exemple, favorise exclusivement l’exploration, et conduira son utilisateur systématiquement dans cette voie, quel que soit le contexte.
Meilleur prompt, plus de contexte : rien n’y fait
« Pour nous débarrasser de ces biais, nous avons utilisé tout ce qui est considéré comme bonnes pratiques en matière de prompts », raconte Llewelyn Thomas : changer l’ordre de présentation des options, changer le point de vue, demander une analyse des avantages et des inconvénients… Sur les deux premières tensions (différentiation/commoditisation et augmentation/automatisation), ces changements n’ont eu aucun effet. Sur les 5 autres, le changement de prompt a entraîné une plus grande variabilité des réponses, mais celle-ci était due pour l’essentiel à un seul facteur : l’ordre de présentation des options. Ces agents conversationnels ne sont donc pas plus pertinents sur ces dimensions ; ils sont simplement influencés par l’agencement de l’information.
Les biais disparaissent-ils si l’on ajoute du contexte ? Un cas d’entreprise plus détaillé, avec des enjeux sectoriels plus précis, pourrait générer une réponse plus personnalisée. Ce n’est le cas qu’en apparence : les réponses sont légèrement plus dispersées, mais restent largement biaisées. En somme, c’est pire : « Un LLM peut donner l’impression d’offrir une solution entièrement sur-mesure pour votre situation, tout en vous orientant subrepticement vers le même ensemble de tendances managériales à la mode », analysent les chercheurs. Les LLM n’analysent pas spécifiquement votre situation : ils vous proposent une version bien huilée de réponses populaires qui sonnent bien. »
« Les LLM ont tendance à être complaisants »
Comme le font remarquer les chercheurs, la commoditisation, le fait d’aller chercher des marchés plus vastes en réduisant les coûts et les prix, est souvent une bonne stratégie. En ne la recommandant jamais, l’intelligence artificielle fait à l’évidence un mauvais travail. Comment fonctionnent ces biais ? « “Commoditisation”, “réduction des coûts” ne sont pas des termes heureux ou chaleureux, explique Llewelyn Thomas. À l’inverse, “différentiation”, “être spécial”, “être unique” sont des notions dont la valence émotionnelle est beaucoup plus élevée. On sait que les LLM ont tendance à être complaisants. »
Pour Llewelyn Thomas, ce défaut pourrait possiblement être combattu par un meilleur entraînement des moteurs. Mais il y a un autre sujet, qui est celui de la qualité et de la quantité des données utilisées. « Les LLM ne sont pas entraînés uniquement sur la littérature académique. Certes, sur la commoditisation, vous avez une littérature importante. Mais en face, il y a la masse des posts Substack où les auteurs vantent leur différence, leur unicité, leur spécialisation… » Il y a un problème structurel de qualité et de quantité des données utilisées par les LLM.
Peut-être pourrait-on demander au LLM de pondérer différemment les données ? Pas vraiment. « Il faudrait dire au modèle : “Ne fais pas confiance aux données qui pèsent le plus lourd, fie-toi aux corrélations les plus faibles.” Et si vous allez dans cette direction, le modèle se mettra à vous dire qu’on n’est jamais allés sur la Lune, qu’Elvis n’est pas mort et vit à Bruxelles, etc. » En définitive, « c’est un problème qu’il n’est pas facile de résoudre par l’ingénierie ».
Le « piège de l’hybride », ou la tentation du non-choix
Il restait un dernier biais à neutraliser : lors des premières vagues de tests, les LLM étaient contraints à un choix binaire entre deux stratégies, collaboration ou coopération, court terme ou long terme, etc. « Nous nous sommes demandé ce qui se passerait si nous supprimons l’obligation de trancher, ce qui nous rapprocherait des conditions dans lesquelles la plupart des stratégistes travaillent. »
Résultat : ChatGPT (testé dans ces conditions) reste biaisé dans la même direction, mais avec une tendance à tomber dans le « piège de l’hybride », c’est-à-dire la tentation de ne pas vraiment choisir et de se retrouver à courir deux lièvres à la fois. C’est particulièrement le cas sur les axes exploitation/exploration (plus de la moitié des réponses) et innovation radicale/innovation incrémentale (41 % des réponses). En clair, quand on leur demande de choisir, les LLM optent pour les tendances à la mode ; et quand on leur permet de ne pas trancher, ils ne s’en privent pas.
Un point intéressant de l’étude est qu’elle se fonde sur des cas de stratégie eux-mêmes créés partiellement… par intelligence artificielle. « Nous avons utilisé des LLM pour créer des brouillons de cas, que nous avons ensuite revus et réécrits pour nous assurer qu’ils étaient cohérents. Ce sont donc des cas uniques, ils n’existent nulle part sur le web. » Les contextes choisis correspondent ainsi en quelque sorte à la moyenne des cas existants dans chaque domaine donné.
À la suite de la publication de cette étude, « nous avons été contactés par des laboratoires de pointe (frontier labs) », y compris par les fondateurs de l’un des LLM utilisés. Pour le moment, cependant, il semble bien qu’il n’y ait pas vraiment de perspective à court terme de voir les agents conversationnels utilisant des modèles de langage produire du conseil en stratégie viable. Ce qui ne veut pas dire qu’ils sont inutiles au consultant. Comme le résume Llewellyn Thomas, les LLM restent « excellents pour stimuler la pensée divergente. Mais ils sont médiocres pour vous aider à converger vers une stratégie ».

Un tuyau intéressant à partager ?
Vous avez une information dont le monde devrait entendre parler ? Une rumeur de fusion en cours ? Nous voulons savoir !
commentaires (1)
citer
signaler
Monde
 01/06/26
01/06/26Avec 1,01 milliard d’euros de chiffre d’affaires l’an dernier, Roland Berger franchit ce seuil symbolique pour la seconde fois après 2023.
 01/06/26
01/06/26Après plus de 25 ans au BCG à Paris, le spécialiste des secteurs grande conso et luxe Stéphane Cairole va présider aux destinées du bureau de la deuxième ville helvétique.
 28/05/26
28/05/26Un directeur de Kearney au bureau d’Abou Dabi a diffusé à sa communauté un titre « Drum & Bass » effréné où il décrit le quotidien de ses pairs.
 25/05/26
25/05/26Le royaume aurait également gelé certains paiements dus aux cabinets occidentaux – jusqu’en juillet.
 25/05/26
25/05/26François de Bodinat rejoint Oliver Wyman à Newcastle comme managing director products & assets.
 19/05/26
19/05/26CIB Consulting & Transformation ouvre à Mumbai et recrute notamment deux profils seniors pour piloter son développement local.
 18/05/26
18/05/26Le cabinet évoque la simplification d’un système de rémunération devenu complexe.
 09/05/26
09/05/26D’ici la fin de l’été, McKinsey aura déployé mondialement des agents IA pour affecter des consultants sur les missions – alors que la perspective d'une réduction de 10 % de ses fonctions support avait fuité en décembre 2025.
 07/05/26
07/05/26Managing partner France-Maroc depuis 2024, Matteo Ainardi conserve ses fonctions et voit son périmètre élargi.